
Insights
Which AI Model Is Best at Predicting Football? We Tested 10 Models Across 144 Matches
We put 10 leading AI models — from Claude Sonnet to GPT-4o — head-to-head across 144 real football fixtures to find out which one is genuinely best at predicting match outcomes. The results, tracked live on TuringStats, reveal a clear winner and some surprising upsets in the AI prediction race.
The Question Every Football Fan Is Asking in 2025
Artificial intelligence has transformed almost every industry it has touched, from medical diagnostics to financial forecasting. But can it crack the beautiful game? Football — with its chaotic deflections, managerial whims, and late red cards — has long been considered the nemesis of statistical prediction models. Yet a new generation of large language models (LLMs) is taking on the challenge, and the results are more compelling than most analysts expected.
TuringStats, a platform dedicated to benchmarking AI football predictions in real time, has been running one of the most rigorous independent tests of AI prediction accuracy ever conducted. Across 144 real football fixtures — spanning top European competitions including the UEFA Champions League — ten of the world's most advanced AI models have been pitted against each other to answer one simple question: which AI is best at predicting football?
The leaderboard is live, the data is impartial, and the findings are genuinely surprising. Let's break it all down.
How TuringStats Measures AI Prediction Accuracy
Before diving into the rankings, it is worth understanding the methodology, because not all prediction benchmarks are created equal. TuringStats uses two primary metrics to evaluate each model's performance.
The first is Hit Rate, which measures the percentage of matches where the AI correctly predicted the outcome (win, draw, or loss). This is the most intuitive measure of accuracy — if you say Manchester City will beat Burnley and they do, that counts as a hit. Hit Rate is easy to understand but can mask the quality of a model's probabilistic reasoning.
The second metric is the Brier Score, a more sophisticated measure borrowed from meteorological forecasting. The Brier Score evaluates the accuracy of probability estimates: a model that assigns a 90% probability to the correct outcome scores better than one that only assigns 51%. Crucially, lower Brier scores are better — a perfect model would score 0.00. A model that blindly assigns equal probabilities to all outcomes would score around 0.67. This means a Brier Score below 0.67 indicates genuine predictive value, while anything above suggests the model is performing worse than random.
Every model on the TuringStats leaderboard has evaluated the same set of fixtures under the same conditions, making this one of the most level playing fields in AI sports prediction research.
The Full AI Football Prediction Leaderboard
Here is the complete leaderboard as of 144 fixtures decided:
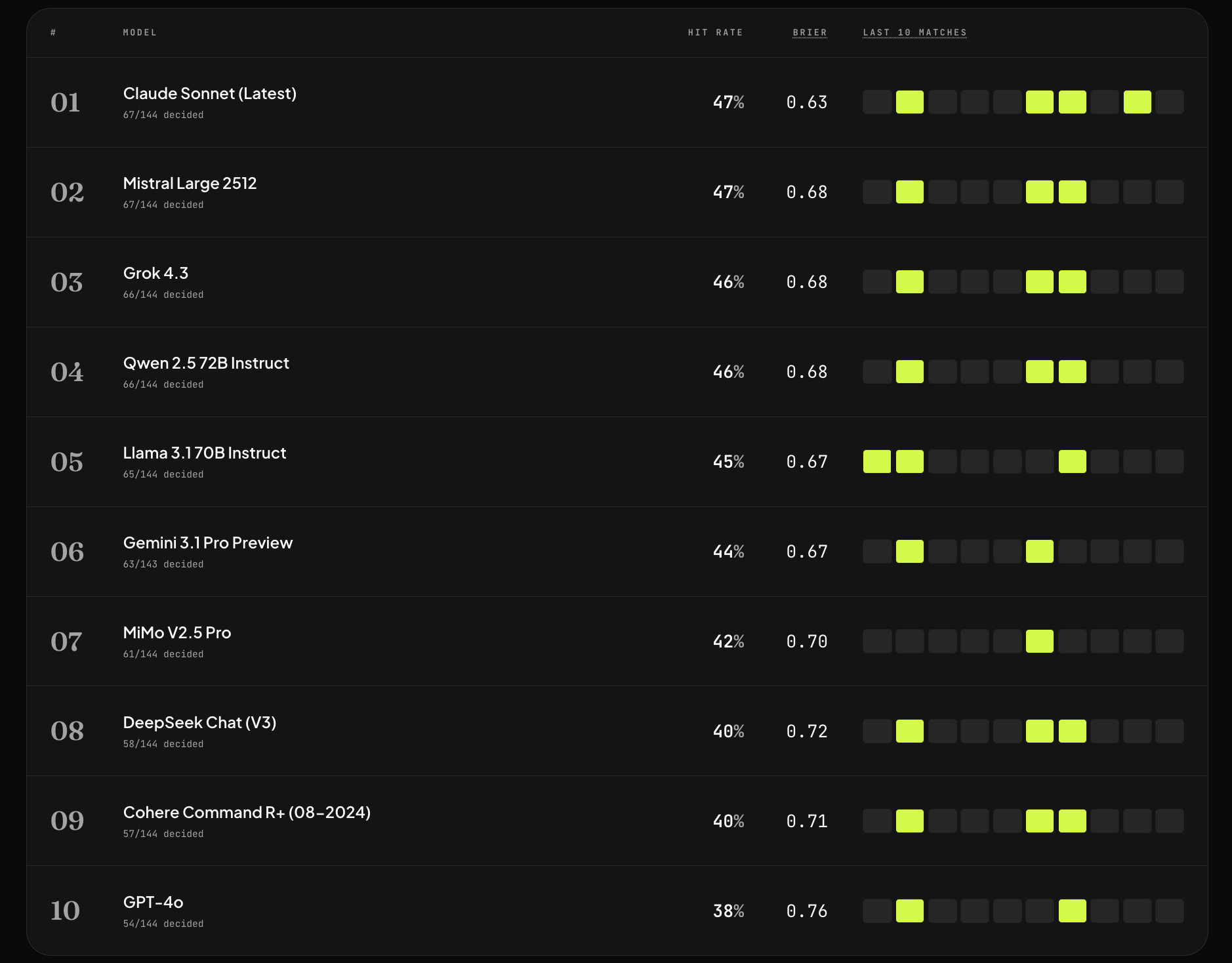
#1: Claude Sonnet (Latest) — The Reigning Champion
Anthropic's Claude Sonnet (Latest) sits at the top of the leaderboard with a 47% hit rate — matching Mistral but pulling ahead decisively on the Brier Score, where it records a class-leading 0.63. This is a genuinely impressive figure. Remember that a random baseline scores around 0.67 — Claude Sonnet is not only getting more predictions right, it is also placing its probability estimates with considerably greater confidence and accuracy.
What makes this result particularly significant is that it demonstrates a key distinction between LLMs: raw reasoning ability versus calibrated probabilistic thinking. Claude Sonnet does not just guess the right team; it assigns probability distributions that reflect real uncertainty in a match, and it does so more accurately than any other model tested. For anyone looking for the most trustworthy AI football prediction tool available today, the data points clearly to Claude Sonnet as the benchmark.
Anthropic has invested heavily in Claude's ability to reason carefully under uncertainty, and that design philosophy appears to be paying dividends in sports forecasting — a domain that demands nuanced probability estimation over confident but poorly-calibrated guesses.
#2: Mistral Large 2512 — Tied on Hit Rate, but Falls Short on Calibration
French AI company Mistral's flagship model, Mistral Large 2512, lands in second place with an identical 47% hit rate to Claude Sonnet and the same sample size of 67/144 decided matches. On the surface, these two models appear indistinguishable. But the Brier Score tells a different story.
Mistral Large 2512 records a Brier Score of 0.68 — five points worse than Claude's 0.63, and notably sitting just above the random baseline of approximately 0.67. This means that while Mistral gets the correct outcome just as often as Claude, its probability estimates are less reliable. In practical terms, a bettor or analyst relying on Mistral's confidence percentages would be getting noisier signals than someone using Claude's output.
That said, Mistral Large 2512 is unquestionably a top-tier performer and represents a remarkable achievement for a European AI lab competing directly with the world's leading models. Its ability to match Claude on raw accuracy while covering 144 fixtures speaks to genuine football understanding, even if its probabilistic calibration needs refinement.
#3 and #4: Grok 4.3 and Qwen 2.5 72B Instruct — The Joint Bronze Medalists
Two more models share the third and fourth positions with 46% hit rates and identical Brier Scores of 0.68. Grok 4.3, developed by xAI (Elon Musk's AI venture), and Qwen 2.5 72B Instruct, developed by Alibaba Cloud's research division, are separated only by a single correctly predicted fixture (66 versus 66 in the same pool).
Grok 4.3's performance is a notable achievement for a relatively young AI lab. The model has built a reputation for bold, direct reasoning — traits that appear to translate reasonably well to football prediction, where confident probabilistic thinking is rewarded. Its Brier Score of 0.68 means it is essentially performing at the random baseline on calibration, but its raw hit rate of 46% confirms genuine predictive ability.
Qwen 2.5 72B Instruct, Alibaba's open-weight powerhouse, matches Grok stride for stride. The 72-billion-parameter model has been widely praised in the AI research community for its multilingual reasoning capabilities, and its 46% hit rate suggests that large open-weight models are far from outclassed by proprietary alternatives when it comes to sports forecasting.
#5: Llama 3.1 70B Instruct — Meta's Open-Source Contender
Meta's Llama 3.1 70B Instruct occupies fifth place with a 45% hit rate and a Brier Score of 0.67 — the joint-best calibration score among models ranked third through sixth. The fact that Llama 3.1 70B can compete with proprietary models costing orders of magnitude more to run is a remarkable validation of Meta's open-source strategy.
For developers and researchers looking to deploy AI football prediction at scale, Llama 3.1 70B represents a compelling option: near-top-tier accuracy at a fraction of the infrastructure cost. Its Brier Score of 0.67 — right at the random baseline — suggests that while it is not dramatically better than chance at probability estimation, it is also not systematically worse, which is more than can be said for several models ranked below it.
#6: Gemini 3.1 Pro Preview — Google's Model Shows Promise
Google DeepMind's Gemini 3.1 Pro Preview rounds out the top six with a 44% hit rate and a Brier Score of 0.67. Having evaluated 63 out of 143 decided fixtures (slightly fewer than most competitors), Gemini 3.1 Pro Preview's performance is still statistically meaningful but slightly harder to compare on a like-for-like basis.
Its performance reflects the broader trajectory of Google's Gemini lineup: competitive, improving rapidly, but not yet at the very top of the prediction pyramid. The 44% hit rate puts it one to three percentage points behind the leading cluster, a gap that is small in absolute terms but meaningful when projected across a full football season of predictions.
#7: MiMo V2.5 Pro — The Specialist Model Falls Short
MiMo V2.5 Pro, positioned seventh with a 42% hit rate and a notably higher Brier Score of 0.70, marks a more significant drop-off in both raw accuracy and calibration quality. The model has 61 correct predictions out of 144 decided fixtures — a reasonable total in absolute terms, but one that places it clearly behind the top six.
The Brier Score of 0.70 is particularly telling. At this level, the model's probability estimates are actively misleading compared to a random baseline, suggesting that while MiMo V2.5 Pro can identify clear favourites, it overestimates or underestimates probabilities in close matches — a common failure mode for models that have been optimised for reasoning tasks rather than calibrated probabilistic forecasting.
#8 and #9: DeepSeek Chat (V3) and Cohere Command R+ — The Lower Tier
DeepSeek Chat (V3) and Cohere Command R+ (08-2024) both register 40% hit rates, placing them in eighth and ninth position respectively. DeepSeek's Brier Score of 0.72 and Cohere's 0.71 both represent a meaningful step below the calibration threshold, indicating that these models are not only getting fewer predictions right but also expressing poorly calibrated confidence in their wrong calls.
DeepSeek has generated enormous attention in the AI world for its cost-effective reasoning capabilities, and its performance in coding and mathematics benchmarks has been genuinely exceptional. Football prediction, however, appears to expose a different kind of reasoning gap — one where nuanced contextual understanding of team form, tactical matchups, and situational variance matters more than raw computational reasoning.
Cohere Command R+ (08-2024) was released in 2024, making it one of the older models in this comparison. Its 40% hit rate still represents genuine predictive ability — significantly above the performance of a pure guess — but it is clear that newer and larger models have developed football prediction capabilities that Command R+ cannot match.
#10: GPT-4o — The Surprising Underperformer
The most eyebrow-raising result in the entire leaderboard is the position of OpenAI's GPT-4o. With a 38% hit rate — the lowest of any model tested — and a Brier Score of 0.76, GPT-4o lands at the bottom of the rankings. This result will shock many observers: GPT-4o is widely considered one of the most capable general-purpose AI models in existence, yet across 54 decided fixtures out of 144, it has demonstrated the weakest prediction accuracy and the worst probabilistic calibration of the entire field.
There are several potential explanations for this underperformance. First, GPT-4o's training may optimise for a different kind of helpfulness — providing thorough, balanced analyses rather than committing to sharp probability distributions. In football prediction, decisiveness and calibrated probability assignment matter more than nuanced multi-perspective reasoning. Second, OpenAI's model may be more susceptible to recency bias or overweighting headline narratives (such as a team's star player being in form) rather than underlying structural metrics.
It is also worth noting that GPT-4o has only 54 decided fixtures — the fewest of any model tested — which introduces more statistical variance into its results. A larger sample may partially rehabilitate its standing. But even accounting for this, its Brier Score of 0.76 represents a genuinely poor calibration result, and the gap to the leading cluster is too large to be dismissed as statistical noise.

What Does This Mean for AI Football Prediction in Practice?
The TuringStats leaderboard raises several important implications for anyone thinking about how to use AI in sports analysis.
The first takeaway is that model choice matters enormously. A 9-percentage-point gap in hit rate between first-place Claude Sonnet (47%) and last-place GPT-4o (38%) is substantial — over a season of 380 Premier League fixtures, that difference translates to approximately 34 additional correct predictions. If you are using AI to inform betting strategies, squad analytics, or editorial content, the model you choose has a direct and material impact on accuracy.
The second takeaway is that Brier Score is a more important metric than Hit Rate for serious practitioners. Claude Sonnet's 0.63 Brier Score is not just incrementally better than GPT-4o's 0.76 — it represents a fundamentally different quality of probabilistic reasoning. When an analyst needs to know not just who will win, but how confident to be in that prediction, Claude Sonnet's calibrated estimates are significantly more valuable.
Third, open-source models are genuinely competitive. Llama 3.1 70B Instruct (Meta) and Qwen 2.5 72B Instruct (Alibaba) both outperform GPT-4o, which costs considerably more to access via API. For teams building prediction pipelines at scale, the open-weight ecosystem is no longer a compromise — it is a legitimate first choice.
Why Football Is the Ultimate Test of AI Reasoning
Football prediction is harder than it looks, and that difficulty is precisely what makes the TuringStats experiment so valuable as an AI benchmark. Unlike chess or Go — where the rules are fixed and the state space is finite — football involves an enormous number of variables that are difficult to quantify: referee decisions, weather conditions, player psychology, tactical in-game adjustments, and the sheer randomness of a ball hitting a post versus going in.
Traditional quantitative models — Expected Goals (xG), Elo ratings, Dixon-Coles match outcome models — have made significant progress in capturing team-level performance trends, but they struggle with context-rich scenarios: a depleted squad, a must-win Champions League knockout, a managerial sacking three days before a fixture. Large language models, trained on vast corpora of football journalism, tactical analysis, and match reports, theoretically have access to exactly this kind of qualitative context.
The TuringStats results suggest that the best models — particularly Claude Sonnet — are beginning to synthesise quantitative signals with contextual understanding in ways that approach the accuracy of expert human analysts. A 47% hit rate is not dramatically better than an informed human analyst, but when combined with a 0.63 Brier Score, it suggests that Claude Sonnet's confidence levels are well-founded — it is not just guessing right nearly half the time, it knows when it is more and less certain.
The Broader Race: AI Model Rankings and Football
This leaderboard is more than a curiosity for football fans. It is a revealing window into the different strengths and weaknesses of the AI systems that are increasingly being integrated into media, finance, and enterprise decision-making.
The fact that Claude Sonnet leads on probabilistic calibration (Brier Score) while matching Mistral on raw accuracy suggests that Anthropic's Constitutional AI training process — which emphasises honest, well-calibrated responses — may confer real-world advantages in uncertain prediction tasks. The fact that GPT-4o underperforms so significantly challenges the popular assumption that the most famous AI model is necessarily the most capable in every domain.
As AI models become more deeply embedded in sports analytics — from injury risk modelling to transfer market valuation — results like these will increasingly inform which models clubs, broadcasters, and betting operators choose to deploy. The stakes are rising, and the leaderboard is becoming a genuine measure of commercial value, not just academic curiosity.
How TuringStats Runs the Benchmark
The methodology behind TuringStats is straightforward but rigorous. Before each matchday, every AI model on the platform is asked to provide its prediction for each fixture, including a probability distribution across the three possible outcomes (home win, draw, away win). Those predictions are locked before kick-off, eliminating any possibility of post-hoc adjustment.
After full time, the results are automatically scored. Hit Rate is calculated as the proportion of matches where the model's modal prediction (the outcome it assigned the highest probability) matched the actual result. Brier Score is calculated using the standard formula: the mean squared difference between the predicted probabilities and the actual outcomes (represented as 1 for the correct outcome, 0 for incorrect).
The "Last 10 Matches" column in the leaderboard shows each model's most recent form, providing a dynamic view of whether models are improving or deteriorating over time — a crucial feature for anyone tracking model updates and version changes. The platform currently covers 144 fixtures across top competitions, a sample size large enough to produce statistically meaningful rankings.
Looking Ahead: Can Any Model Crack the 50% Barrier?
One of the most tantalising questions raised by the TuringStats data is whether any AI model will consistently break the 50% hit rate barrier across a large sample of fixtures. To put this in context, professional football tipsters with genuine edge typically achieve hit rates of between 50% and 55% over meaningful sample sizes. The best quantitative models in the industry operate in a similar range.
Claude Sonnet's 47% figure, while impressive in context, still falls short of this threshold. The model is making correct predictions on approximately 9 out of every 20 matches — a rate that beats random chance but does not yet meet the bar set by the best human experts. As models continue to evolve — absorbing real-time data, fine-tuning on football-specific corpora, and developing better reasoning about tactical context — the 50% barrier seems genuinely achievable within the next one to two model generations.
Mistral, Grok, and Qwen are all within two percentage points of the leader, and the competitive dynamics of the AI market mean that all four models will receive significant updates in the coming months. The TuringStats leaderboard will be a fascinating document of that evolution.
Verdict: Claude Sonnet Is the Best AI for Football Prediction — For Now
Based on the most comprehensive independent benchmark of AI football prediction available, the answer is clear: Claude Sonnet (Latest) is currently the best AI model for predicting football outcomes. Its 47% hit rate is matched by Mistral, but its Brier Score of 0.63 sets it apart as the most calibrated and reliable probabilistic predictor in the field.
For fans, analysts, and developers looking to integrate AI into their football workflows, the data from TuringStats offers three concrete recommendations. Use Claude Sonnet if accuracy and calibration are your primary requirements. Consider Mistral Large 2512 or Grok 4.3 as strong alternatives if API cost or deployment flexibility are factors. And do not assume that brand recognition translates to prediction quality — GPT-4o's last-place finish is a clear reminder that the most famous model is not always the most capable one for every task.
The AI football prediction race is far from over. But right now, after 144 fixtures and 10 models, there is a clear winner — and it might surprise you.
This analysis is based on live leaderboard data from TuringStats. Rankings and Brier Scores reflect performance across 144 fixtures and may be updated as more matches are decided. Visit TuringStats.com for live predictions and the latest model standings.











